人工智能在工业预测性维护中的真实面目:从狂热到落地
去年参加一个行业闭门会,某知名车企的设备总监拍桌子说:“谁再跟我忽悠人工智能预测维护,我就把谁踢出供应商名录。” 现场一片死寂,然后是零星的掌声。说实话,这事儿我一点都不意外。人工智能在工业圈的火,烧得有点虚。可就在同一天,另一家小厂却靠着自研的振动分析模型,把非计划停机砍掉了七成。冰火两重天——这才是真实世界的工业人工智能。
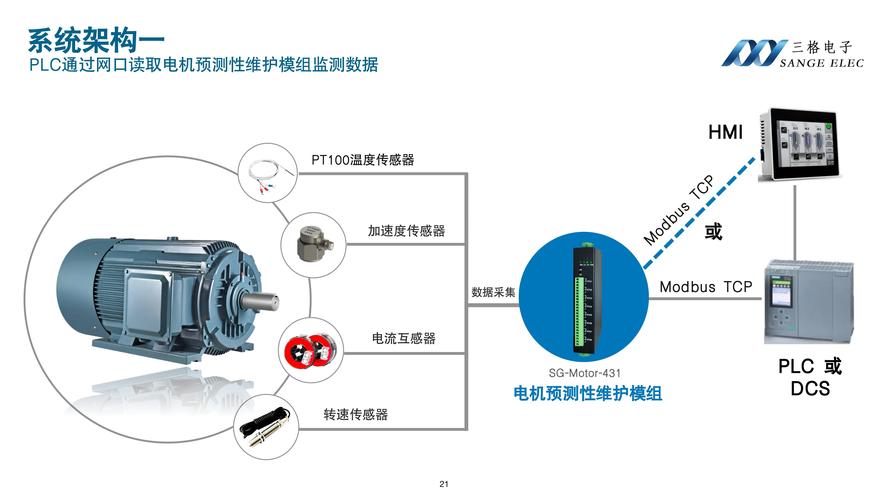 预测性维护传感器安装于工业电机
预测性维护传感器安装于工业电机
为什么多数项目死在PoC(概念验证)阶段?唉,这是个血泪交织的问题。先别急着谈算法,咱们得从车间地面上的油污说起。工业现场的数据,脏得超乎想象。传感器丢包、时间戳对不齐、工况标签缺失……更有趣的是,操作工习惯性在交接班记录上写“一切正常”,哪怕设备已经发出吱嘎异响。这种“正常”数据喂给机器学习模型,结果可想而知。
数据!数据!数据!——人工智能的阿喀琉斯之踵
 数据!数据!数据!——人工智能的阿喀琉斯之踵
数据!数据!数据!——人工智能的阿喀琉斯之踵
我见过最离谱的项目:一家化工厂装了800个测点,半年攒了2TB数据,信心满满扔进深度学习模型。结果准确率不到40%——比抛硬币强点有限。细查才发现,90%的数据都是设备停机或待机状态,核心故障样本只有可怜的17条。这能训练出什么?巧妇难为无米之炊。
💡 别迷信大数据。工业预测维护的关键是有效故障样本。有些老法师的做法更实在:故意在试验台上搞破坏,人为制造不平衡、不对中、轴承磨损,采集“带血”的数据。虽然听起来粗暴,但比干干净净的“正常”数据有用一百倍。
问:我们工厂设备老旧,连PLC都没接全,能上人工智能预测维护吗?
答:能,但别指望一步登天。可以从外加传感器入手——振动、温度、电流,这些都是非侵入式的。先用规则引擎和阈值报警跑起来,积累数据的同时解决一些显性问题。等到有了一定量的标定故障数据,再尝试轻量级机器学习模型,比如随机森林或者XGBoost。千万别一上来就深度学习,那是个无底洞。
从“传感器数据”到“停机决策”:模型训练的那些坑
很多人以为模型训练就是调参,真正的硬骨头是特征工程。举个例子,一台离心泵的振动信号,时域波形、频谱、包络谱……你需要从上百个备选特征里挑出对轴承磨损最敏感的那几个。这靠的不是数学,是工艺经验和物理直觉。有次为了捕捉一种罕见的气蚀现象,我们对着频谱图看了三天,最后发现某个高频带的能量比突变比所有经典特征都提前6小时报警。那一刻的兴奋,不亚于中了彩票。
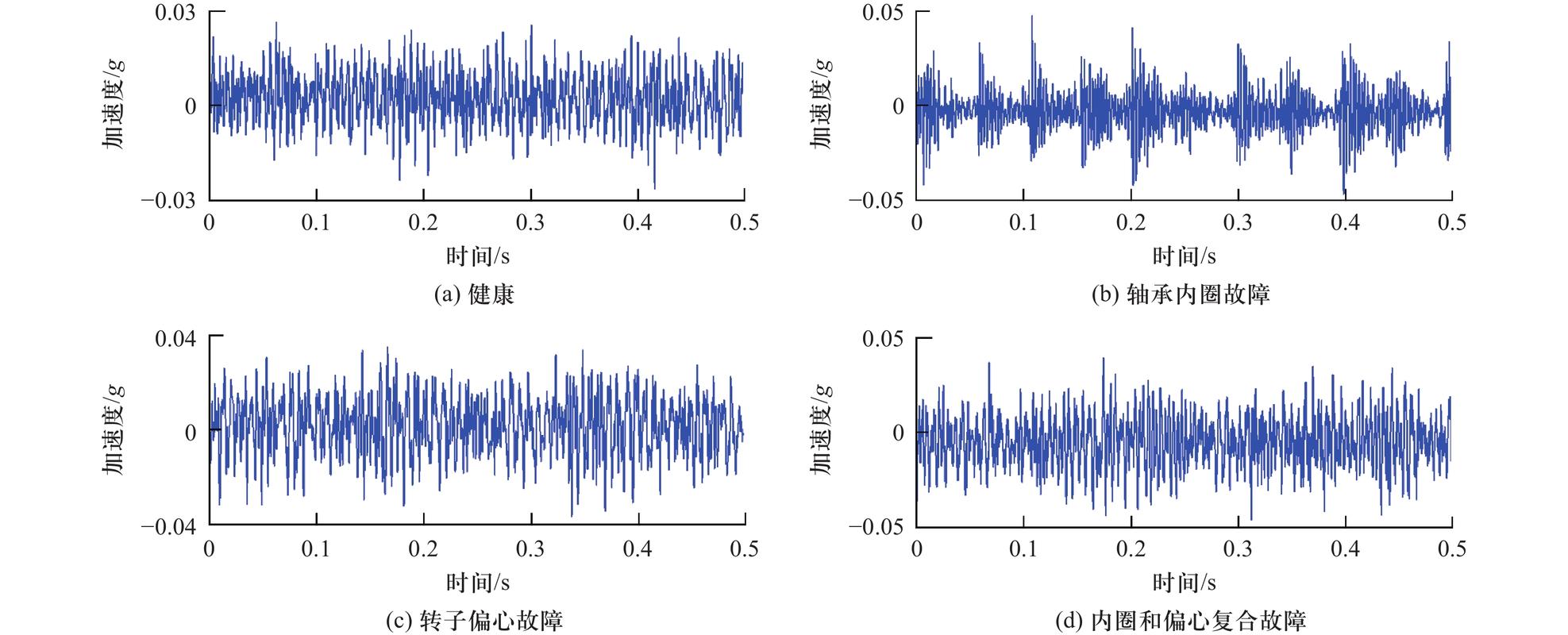 振动频谱分析对比正常与故障状态
振动频谱分析对比正常与故障状态
问:预测性维护真的能减少80%停机时间吗?这个数字是不是吹牛?
答:数字本身不假,但前提条件苛刻。只有在设备关键度高、故障模式明确、数据基础扎实的情况下才有可能达到。大部分工厂能减少30%~50%非计划停机就相当不错了。更要命的是,预测维护的收益很难量化——你避免了这次故障,但谁知道它原本会不会发生?这需要和被动维修的历史成本做对比,可很多企业压根没记过这些账。
别只盯着预测,闭环才是王道
 别只盯着预测,闭环才是王道
别只盯着预测,闭环才是王道
前几天一个朋友吐槽,他们模型提前48小时预警了变速箱故障,可维修团队不当回事,愣是等到设备趴窝。这就是决策闭环断裂。人工智能在工业里绝不能是孤立的技术飞地,它得融入点检、备件、排产系统。搞预测维护的人必须和维修班长拜把子——否则你的报警永远是屏幕上的装饰。
❗ 还有一个被忽视的真相:人机协同。最好的预测系统不是替代老师傅,而是放大他们的耳朵和眼睛。把模型输出的概率、关键特征贡献度用可视化推送到手机,让巡检人员结合现场听音、摸温做最后判断。这比追求全自动要靠谱得多。
问:既然坑这么多,中小企业还有必要搞人工智能预测维护吗?
答:非常有必要,但一定要“小步快跑”。可以从最痛的设备做起,比如瓶颈工序的关键机床。先用低成本方案验证效果,见到收益再扩展。千万别听供应商画饼,搞什么“一网打尽”的平台。我见过最成功的案例,是一家只有三台注塑机的作坊——老板自己买了几个加速度传感器,用Python搭了极简模型,硬是把模具意外损坏降到了零。
说实话,现在行业里对人工智能的追捧有点病态,好像不提深度学习就落伍了。可真正带来价值的,往往是那些扎扎实实的基础工作:理顺数据采集、标定故障标签、打通工单流程。人工智能在工业预测维护里,应该是味精,不是主食——提鲜可以,当饭吃会饿死。
夜深了,写到这里忽然想起那个拍桌子的总监。会后我私下问他:如果有一款系统,不吹嘘算法多牛,只承诺踏踏实实帮你把关键设备的数据接全、把老专家的诊断逻辑固化、把维修响应时间缩短一半,你愿意聊聊吗?他沉默了几秒,拿起手机扫了我的微信。看,这才是真实的工业界。