工业大数据落地:预测性维护到底省不省钱?
前两天去苏州一个注塑车间,满手油污的老师傅指着屏幕跟我说,这套系统花了八十万,上线半年——啥用没有。我愣了一下,因为同行案例里,预测性维护可是被吹上天的。他补充道:“不是系统不行,是我们数据太脏了。” 振动传感器装歪了,三个月没人校准,传上来的波形全是毛刺。算法再牛,喂垃圾就吐垃圾。这事让我想写点实在的,不扯那些革命、颠覆的虚词。
说实话,工业大数据圈子里,很多人还没搞清 状态监测 和 预测性维护 的根本区别。前者是告诉你「现在齿轮箱温度高了」,后者得告诉你「再过72小时,轴承失效概率87%」。后者才有价值,对吧?但大部分项目都卡在前一步:数据工程。
 工业预测性维护传感器部署现场
工业预测性维护传感器部署现场
数据基础烂,算法就是空中楼阁
去年一个风机厂商找我聊,他们给叶片装了光纤光栅传感器,每秒产生2万多个数据点。存储成本每年三百多万,但真正用上的只有 转速和温度 两个通道。其他数据呢?躺在Hadoop集群里吃灰。我问他为什么不把振动数据用起来,他苦笑:数据标签根本不全——维修记录还是纸质工单,有些故障代码是工人手写的,OCR识别率不到60%。
这就是现实。不是模型不够好,是工业数据的结构化程度远低于互联网。一个注塑机可能有30个传感器点位,但只有5个点位的数据质量稳定。更别说跨工序的数据融合:MES、SCADA、ERP里的时间戳都对不齐,因为有的用NTP授时,有的靠人工校时,差了十几秒就可能导致误报。❗ 听起来很荒谬?这才是工厂常态。
问:既然数据问题这么多,为什么不先治理数据再上AI?
答:因为治理本身是个无底洞。有一家汽车零部件厂,光清洗数控机床的振动信号就搞了八个月,最后发现采样率设置错误——PLC程序是十年前写的,没人能改。更要命的是,数据治理往往需要停产配合,而生产部门根本不答应。💡 所以现在明智的做法是 「用业务价值反过来牵引数据治理」:先挑一台关键设备,从影响最大的故障模式入手,倒推需要哪些数据,把范围压到最小。比如空压机,只盯准螺杆磨损这一个失效模式,采集高频振动和油液颗粒度,数据清洗压力瞬间就小了。
模型不是最难的,难的是闭环
我见过太多漂亮的Dashboard,但车间主任根本不看。为什么?因为模型给出的预警,维护团队不信任——他们觉得“老张听音辨位比你这玩意儿准”。这不能怪他们,很多项目把 OEE和MTBF 挂在嘴边,却没算过经济账:一次非计划停机损失可能是12万,但一次误报导致的额外巡检成本才200块。如果模型把误报率压到足够低,哪怕漏报率高一点,工厂也能接受。但大部分项目根本不量化这种权衡。
问:那怎么让模型真的用起来?
答:必须走「人机协同」。比如给维修班组配上AR眼镜,系统推送的预警不只显示故障概率,还附带维修步骤和备件库存信息。我们在一个钢厂试过,把振动频谱图直接叠加在AR界面上,引导钳工确认轴承磨损位置,两周后他们就开始主动反馈数据问题了——因为模型帮他们把维修时间从4小时压缩到45分钟。✅ 这才算闭环。另外,模型输出要直接对接 备件采购系统,自动触发订单,不然库存管理跟不上,修也没零件。
 工业AR辅助预测性维护界面
工业AR辅助预测性维护界面
边缘计算为什么突然火了
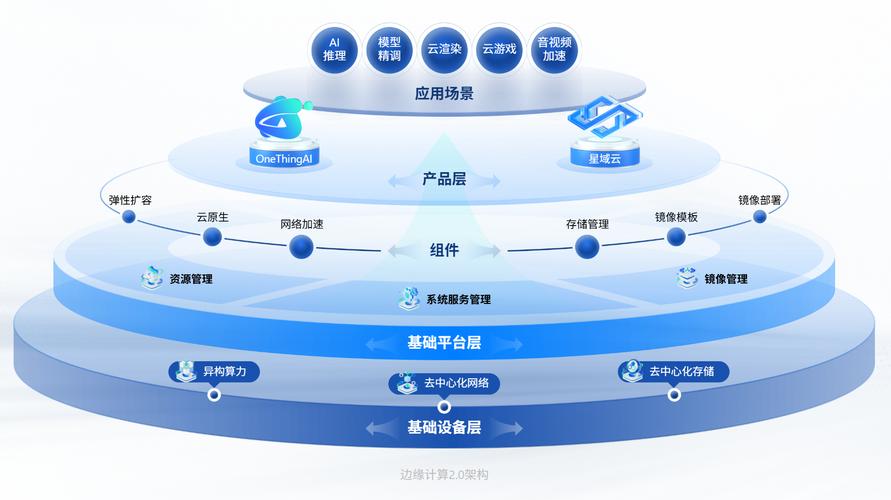 边缘计算为什么突然火了
边缘计算为什么突然火了
这两年有个趋势很明显:把算力推到设备端。去年汉诺威展上,几乎所有工控巨头都在推边缘AI模块。原因很简单——云端的延迟受不了。一个冲压机每分钟120次,如果振动异常需要100毫秒内响应,走云肯定超时。更关键的是,有些数据根本不该离开厂区。军工、动力电池产线对数据主权特别敏感,宁愿多买几块英伟达Jetson,也不开云端传输。
但边缘部署也有坑。⚠️ 算法得做轻量化,TensorFlow Lite转换后精度可能掉5个百分点,需要反复校准。而且边缘设备的散热在油污环境里是个大问题,我们给CNC机床装过一次,夏天直接热宕机。后来加了涡流管冷却才扛住。这些工程细节,才是落地的胜负手。
另外,通信协议也是大麻烦。一个车间可能同时有Profinet、EtherCAT、Modbus,还有老掉牙的OPC Classic。想统一采集到边缘网关,适配工作量巨大。最近OPC UA over TSN开始普及,但老设备改造还是头疼——有的PLC连以太网口都没有,得加串口转接模块,数据丢包率一高,特征提取就全乱套了。
数字孪生:看上去很美
 数字孪生:看上去很美
数字孪生:看上去很美
一说到大数据,数字孪生就跳出来了。说实话,现在90%的数字孪生只是3D动画,跟实际物理状态没有实时映射。真正能用的数字孪生必须基于 高保真的物理模型+实时数据驱动。比如我们给一个石化厂的裂解炉建过,不仅要有几何尺寸,还得耦合流动、传热、反应动力学,这样注入实时进料数据后,才能预测结焦速度,动态安排烧焦周期。但成本呢?建模花了大半年,计算资源每年烧掉几十万。对于中小企业,这账根本算不过来。
不过有一种轻量级数字孪生正在兴起:基于时间序列的虚拟传感器。用历史数据训练一个回归模型,在传感器坏掉的时候,由其他参数推算出缺失值。比如注塑机锁模力传感器故障,可以通过液压缸压力和位置来估算,虽不完美,但能撑过生产高峰,避免停机。✅ 这玩意成本低,见效快,比炫酷的3D有用多了。
但千万别被忽悠去搞什么“全厂数字孪生一张图”。数据基础没打牢时,老老实实从单设备、单工序做起。一台风机、一条传送带,先让数据闭环跑通,再谈扩展。很多项目死在蓝图太大。
人才:比数据更难找
最后吐个槽:懂工业又懂数据的复合型人才稀缺到了离谱的地步。招个计算机毕业生,连轴承长什么样都不知道,特征工程全靠蒙;找个老工程师,Python装不上就放弃。中小企业根本养不起数据团队,靠项目制外包,交付完人走了,系统就慢慢烂掉。我见过一个案例:外包团队离职后,工厂因为没人会改SQL查询,整个看板数据停留在2022年3月。
所以现在行业在推 低代码数据分析平台,让工艺工程师拖拽式构建监测规则。但功能有限,真遇到复杂频谱分析还是抓瞎。最现实的办法是 培养数据员——从设备维护班组里抽人,送到供应商那里培训三个月,回来负责日常数据校验和告警配置。几个厂试点下来,效果居然比外包好,因为人家真心疼设备。
结个尾:别把大数据当万能药
工业大数据一定有用,但我越来越觉得,它首先是个业务问题,其次才是技术问题。如果管理层不把数据资产当真,不给运维团队留出数据校准的时间,不调整KPI把误报和漏报纳入考核,买再多传感器、建再大的数据湖也是摆设。❗ 最怕就是为了跟风申请补贴,搞个面子工程。
所以,如果你们要上预测性维护,先回答我三个问题:1) 最痛的故障是什么?2) 修一次多少钱?3) 有没有三个月不坏的数据? 想不清楚这些,不如把钱省下来,给设备做一次全面润滑。至少那玩意儿不骗人。