“工业软件”突围:别再让“卡脖子”成为老生常谈
做制造这行快二十年了,说实话,提起“工业软件”这四个字,心里总有点五味杂陈。我们车间里的CNC,跑的可能是西门子的控制系统;研发部用的三维CAD,几乎清一色是达索或PTC;仿真?Ansys、Abaqus。前些年还说“买不如造”,可这两年芯片断供一闹,大家突然惊醒——原来工业软件这根“无形的大棒”,挥起来比实体清单更狠。
但惊醒归惊醒,真能破局吗?我看未必。去年参加一个行业闭门会,有专家PPT做得花团锦簇,结论却是“生态建设尚需时日”。一句废话。时日?人家迭代了四十年,等你十年又十年?💡
工业软件的“虚假繁荣”与真痛点
先泼盆冷水。这几年媒体动不动就喊“工业软件国产化率突破X%”,数字好看,可拆开看呢?多数集中在低门槛的MES、轻量级PDM,或者定制的ERP。真正难啃的骨头——比如几何内核求解器、多物理场耦合仿真、高端数控系统的运动控制——依然被牢牢捏在别人手里。这不是危言耸听。拿最基础的CAD几何引擎来说,国内有勇气从头写一个的团队,一只手数得过来。为什么?因为不仅难,还“没用”——市场早被喂习惯了SolidWorks、CATIA,你吭哧吭哧搞出来,生态呢?插件呢?格式兼容呢?
更扎心的是,很多企业喊着自主,其实骨子里还是“拿来主义”。一套所谓的国产PLM,把国外开源内核包个皮,做几个汉化界面,就敢声称自主可控。骗补贴可以,别骗自己。❗
 工业软件几何内核架构示意图
工业软件几何内核架构示意图
不过话说回来,真不能全怪企业。工业软件是工业知识的代码化凝结。人家西门子、达索,背后是数十年与波音、空客、宝马的深度磨合。我们呢?过去二十年,制造大而不强,核心工艺参数都靠老师傅的经验,写在香烟壳上,怎么代码化?没有“工业”,哪来的“工业软件”?这才是最深的痛。
问:中小企业买不起也养不起正版工业软件,难道只能偷偷用盗版?
答:哎,这话问得实在。确实,一套正版Catia或者NX,年费动辄十几万,加上专用工作站和培训,小企业根本扛不住。但盗版终究是饮鸩止渴——数据泄露、技术支持为零,更可怕的是,一旦形成依赖,你所有设计资产都跑在那个非法环境里,某天被查水表,全瞎。现在其实有第三选择:基于云的订阅式工业软件,比如Onshape,或者国内某些SaaS化CAD,几百到几千一个月,按需付费。功能当然没老牌重型软件全,但对一般钣金、夹具设计够用了。再不行,拥抱开源也是个出路,FreeCAD虽然粗糙,但做些简单结构件完全没问题。关键是得转变观念,别觉得非要用最牛的软件才能干活。✅
接回前面。这种“靠经验不靠模型”的后果,正在被放大。现在谈智能制造、数字孪生,前提是你要有可信的、动态的物理模型。没有高保真的CAE仿真,数字孪生就是个3D动画。而仿真背后,是材料数据库、边界条件经验库、算法积累。我们很多企业的仿真,还停留在“给领导看个云图”的阶段,网格划得一团糟,结果连趋势都判断错。这种水平,别说优化,不误导就烧高香了。
自主化:不是替代,是重构
 自主化:不是替代,是重构
自主化:不是替代,是重构
吵吵了很多年的“替换”思维,该变变了。总想着做一套跟CATIA一模一样的东西,然后便宜卖——这条路基本死路。因为你永远在追赶,还永远追不上。为什么?因为对手不会停下来等你,而且你越模仿,越强化了它的标准。
真正的出路,是重构。借着新架构的东风。比如云原生。传统桌面软件是单机思维,安装文件几十个G,模型文件扔共享文件夹。云原生呢?所有人浏览器登录,数据实时协同,计算放在云端GPU集群。这是全新的赛道。在这个赛道上,我们和美国、法国差不多同时起跑。甚至,因为我们在消费互联网里卷出来的云基础设施能力,还有一点先发优势。
再比如AI for Engineering。最近有团队把深度学习用在拓扑优化里,输入设计空间和载荷,几分钟生成一堆轻量化构型,比经验设计师想出来的减重效果更好。这种基于数据驱动的设计范式,可能根本改变CAD的交互逻辑。你想啊,未来打开一个设计工具,不再是画线、拉伸、打孔,而是告诉AI:“我要一个连接两个部件的支架,重量不超过200克,承受500N拉力。” 它直接抛出几个方案让你选。那现有的那些菜单、命令、特征树,就全成了累赘。这个时刻,如果我们有自己的工业AI引擎,有大量真实工况的训练数据,就有机会换道超车。💡
 基于AI的生成式设计拓扑优化结果
基于AI的生成式设计拓扑优化结果
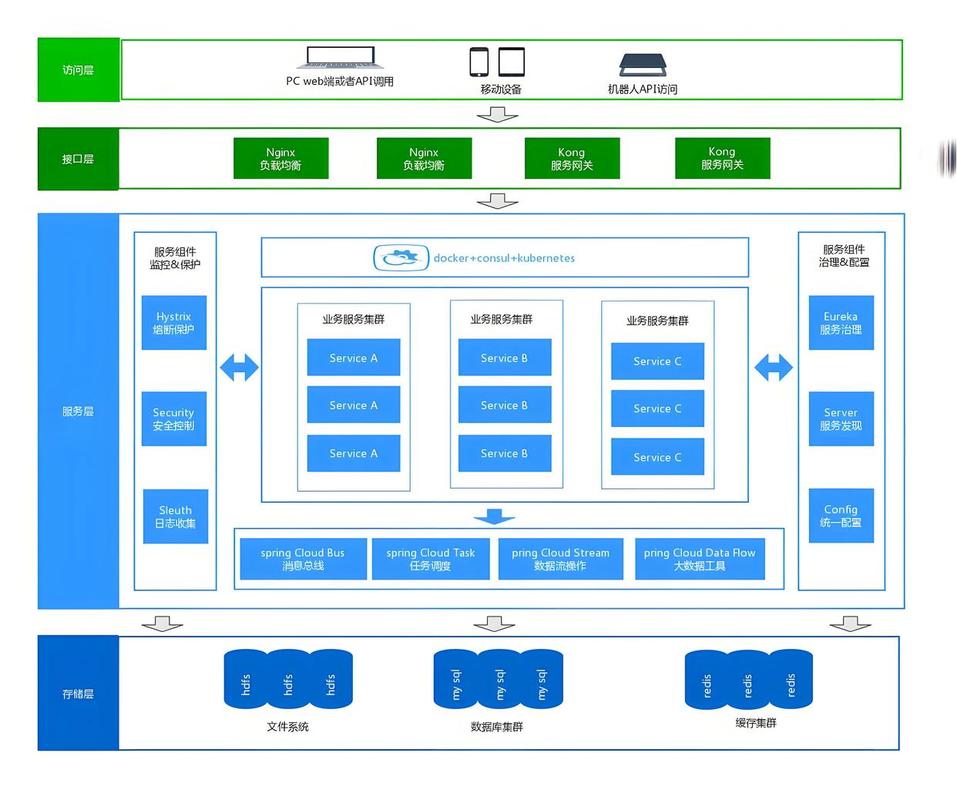
当然,重构需要生态。工业软件最难的是上下游打通。设计完要仿真,仿真完要出工艺卡,工艺卡要驱动机床。这个链条上任何一个环节的缺失,都会让自主化方案落不了地。所幸,这几年看到一些平台型企业开始做“连接器”,比如用工业互联网平台把设计、仿真、制造的数据流串起来。但说实话,现在还处于非常早期的阶段,各种接口标准不统一,数据质量堪忧,而且制造端很多设备连基本的OPC UA都不支持。
问:我们工厂想上数字孪生,但基础数据都在纸面上,怎么起步?
答:太典型了!这是国内工厂的通病。我的建议是:别一上来就想高大上的孪生。先做“数字化”,再做“孪生化”。第一步,把车间里关键设备的状态、产量、故障信息,哪怕用excel手动记录,也给它标准化、在线化。有预算就装些传感器,没预算就人工录入,坚持三个月。第二步,找一两个痛点场景,比如某台关键设备的OEE总是低,用这些数据做分析,建立初步的规律模型。第三步,再考虑三维可视化、实时映射。记住,数字孪生的核心是模型和数据,不是那个酷炫的3D画面。顺序千万别弄反了。❗
下一个战场:云化与AI的变量
 下一个战场:云化与AI的变量
下一个战场:云化与AI的变量
聊到这儿,你可能会想:那到底该怎么干?我的看法很明确——抓两头。
一头是底层的“根技术”。几何内核、求解器、数据库,这些是工业软件的“魂”。国家科研经费应该重点砸在这些地方,像搞高铁、搞北斗那样,组织跨学科团队攻坚。而且必须开源。只有开源,才能吸引开发者,才能构建生态护城河。第二头是顶层的“场景创新”。不要想着做通用大平台去硬刚达索,那是找死。而是要在垂直细分领域,结合国内特有的制造优势,做出杀手级应用。举个例子,新能源电池设计。全球70%的动力电池产自中国,电池的极片设计、化成工艺、Pack结构仿真,这里面有大量独特的物理化学耦合问题,国外的通用软件不好使。如果我们能针对这个场景,开发出专用仿真APP,绑定行业Know-how,那就能牢牢占住一个山头。
再一个变量是“开源与商业的平衡”。很多人一听开源就摇头,觉得赚不到钱。其实完全想错了。Red Hat模式、订阅服务模式、附加增值组件,海外已经趟出了路。我们缺的是耐心和高质量的贡献者。如果能由政府或产业联盟出面,成立一个非营利性的工业软件基金会,持续维护一套基础的工业软件栈(比如开源CAD/CAE内核),鼓励企业在此基础上开发商业套件,那可能是一条健康的道路。
最后,说点丧气但真实的话。工业软件的发展,最终取决于我们的工业文明厚度。当越来越多的工厂愿意为“知识”付费,当工程师不再被鄙视“只会用软件”,当企业主意识到数字化不是面子工程... 到那天,真正的自主工业软件才会水到渠成。在那之前,每一个还在坚持写代码、磨算法的团队,都值得尊重。因为他们敲下的每一行,都是未来不被卡脖子的底气。
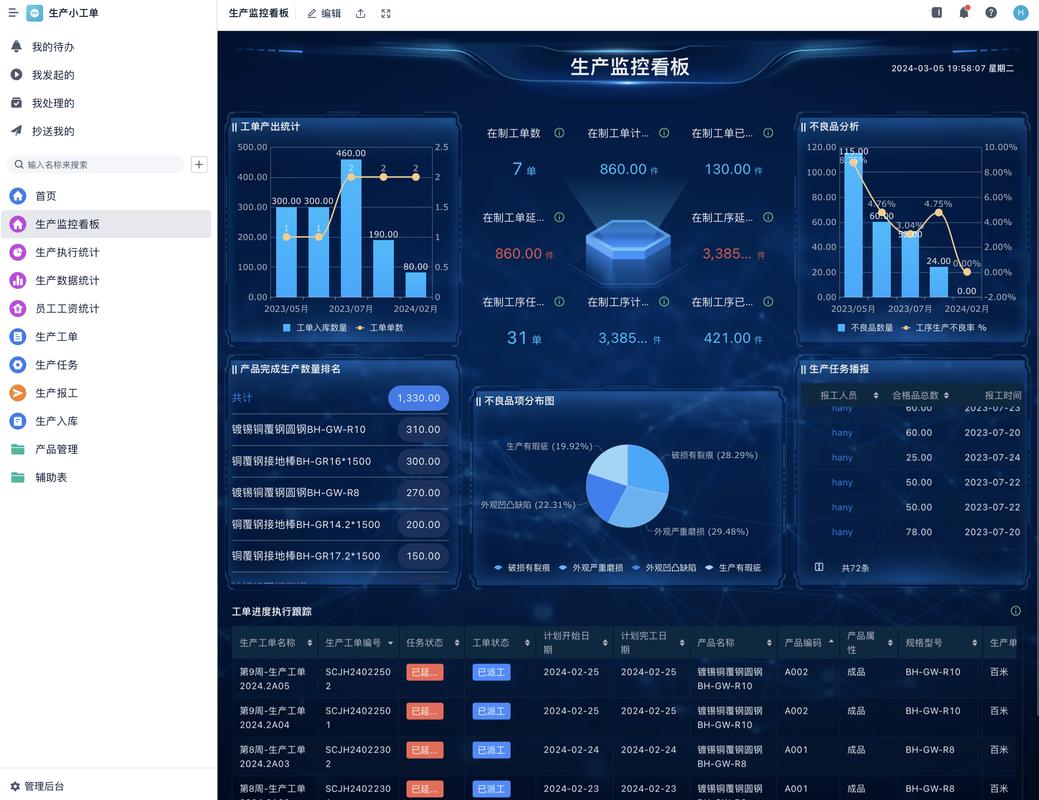 工业互联网平台的车间数据看板
工业互联网平台的车间数据看板
就这样吧。该去调试产线了。😏