
1959 年,亚瑟・塞缪尔在 IBM 实验室里敲下一串代码,让计算机学会了自主下跳棋。这个看似简单的程序暗藏玄机 —— 它能通过分析棋局数据调整策略,胜率随对局次数稳步提升。这便是机器学习的雏形,一场让机器从数据中 “学习” 规律的技术革命由此悄然拉开序幕。如今,当手机相册自动识别人脸,当电商平台精准推送商品,当语音助手理解人类语言,这些日常场景背后,都跳动着机器学习的脉搏。
机器学习的核心逻辑并不神秘。它本质上是让计算机通过算法从数据中挖掘规律,再用这些规律预测未知。就像孩童通过无数次观察区分猫和狗,机器也需要大量标注好的图片数据,才能在 “看” 到新图像时做出判断。这种从经验中提炼规则的过程,被科学家称为 “训练”。训练过程中,算法会不断调整内部参数,直到对已知数据的判断准确率达到预期,这个优化过程如同雕塑家打磨作品,每一次细微调整都让模型更接近 “完美”。
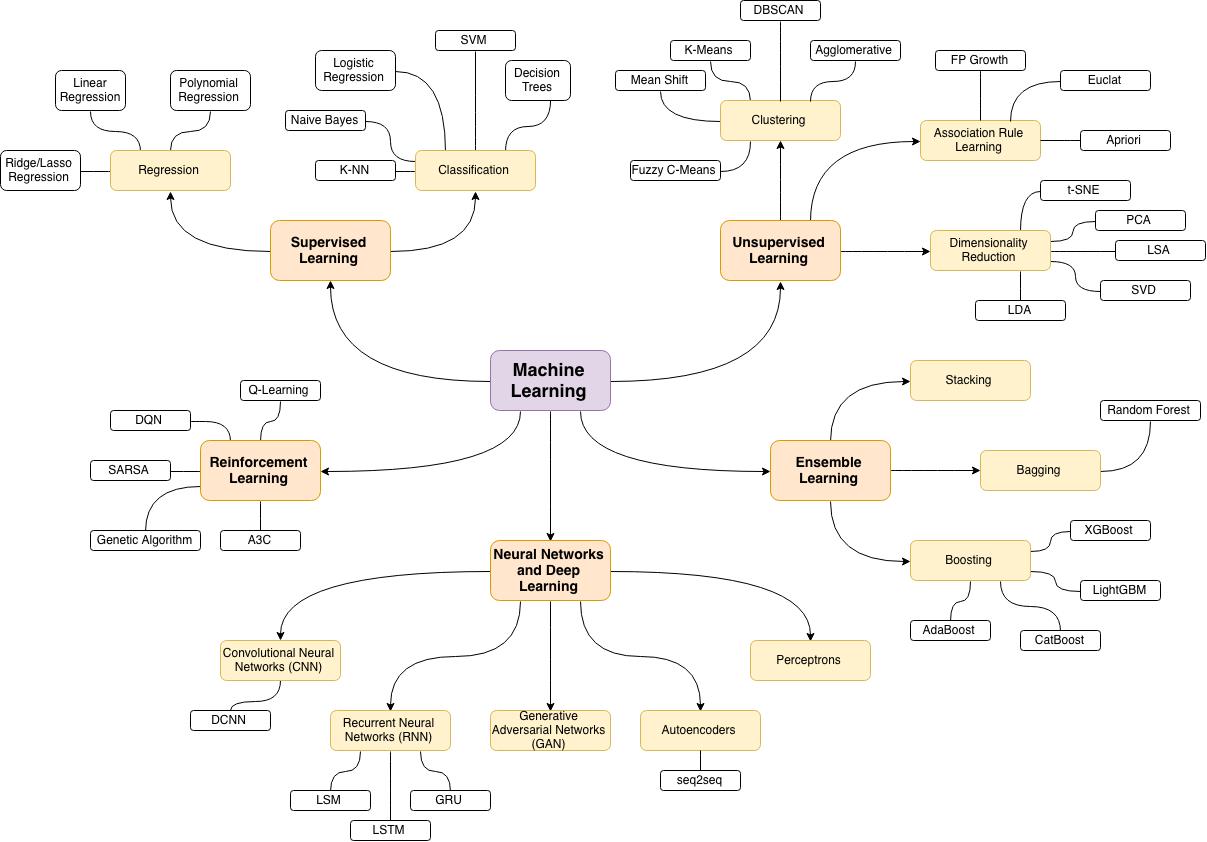
监督学习是目前应用最广泛的机器学习类型。它就像有老师指导的学生,需要在标注清晰的数据中学习。比如银行用客户的收入、负债等历史数据训练模型,预测新客户的还款能力;医院通过病人的症状数据训练系统,辅助诊断疾病。在图像识别领域,监督学习表现尤为出色。2012 年,亚历克斯・克里泽夫斯基团队开发的 AlexNet 模型,在 ImageNet 图像识别大赛中准确率远超传统方法,让机器 “看懂” 世界成为可能。如今,监督学习已渗透到金融风控、医疗诊断、自动驾驶等数十个领域,成为产业升级的隐形引擎。
与监督学习不同,无监督学习更像自主探索的研究者。它不需要人工标注数据,而是通过分析数据的内在结构发现隐藏规律。在电商平台,无监督学习能自动将兴趣相似的用户划分为不同群体,为精准营销提供依据;在基因研究中,它可以从海量基因序列中找到具有相似功能的片段,加速疾病治疗突破。这种无需人工干预的学习能力,让机器在处理未标注的海量数据时如鱼得水,尤其适合探索未知领域的科学研究。
强化学习则模拟了生物进化的过程,通过 “试错” 寻找最优策略。机器在与环境的互动中,会根据行为结果获得 “奖励” 或 “惩罚”,进而调整后续行动。2016 年,谷歌 DeepMind 团队开发的 AlphaGo 正是凭借强化学习,在围棋对弈中击败世界冠军李世石,震惊世界。此后,强化学习在机器人控制、游戏 AI、资源调度等领域大放异彩。它的魅力在于,即使面对规则复杂、状态繁多的环境,机器也能通过持续探索找到解决问题的最佳路径,展现出接近人类的决策智慧。
机器学习的发展离不开数据、算法和算力的协同进步。互联网的普及带来了爆炸式增长的数据,这些数据如同机器学习的 “燃料”,为模型训练提供了充足素材。算法的迭代则让机器的学习效率不断提升,从早期的线性回归到如今的深度学习,每一次算法革新都推动着技术边界向外拓展。而算力的突破更是关键,GPU、TPU 等专用芯片的出现,让复杂模型的训练时间从数月缩短到几天,为大规模应用扫清了障碍。三者相互促进,共同构筑起机器学习的技术大厦。
在医疗健康领域,机器学习正重塑疾病防治的格局。通过分析医学影像,机器学习模型能比人类医生更早发现肺癌、糖尿病视网膜病变等疾病的早期征兆,大幅提高治愈率。在药物研发中,它可以模拟分子结构与疾病靶点的相互作用,将新药研发周期从十年缩短至三到五年,降低研发成本。更令人期待的是,个性化医疗借助机器学习成为可能 —— 根据患者的基因、生活习惯等数据定制治疗方案,让 “对症下药” 达到前所未有的精准度。
金融行业是机器学习应用的先行者。信用卡欺诈检测系统通过分析用户的消费地点、金额、时间等数据,能在毫秒级时间内识别异常交易,每年为银行减少数十亿元损失。智能投顾则根据用户的风险承受能力和收益预期,自动调配股票、基金等投资组合,让普通投资者也能享受专业级的理财服务。在信贷审批中,机器学习模型整合多维度数据评估借款人信用,既提高了审批效率,又降低了坏账风险,让金融服务更加普惠。
零售业因机器学习迎来了体验升级。当消费者在电商平台浏览商品时,推荐系统会根据浏览历史、收藏记录等数据,推送最可能感兴趣的商品,让购物从 “寻找” 变为 “发现”。实体超市则通过分析销售数据和天气、节假日等因素,优化商品库存和摆放位置,减少滞销和缺货情况。无人便利店更是将机器学习与计算机视觉结合,实现自动识别商品、无感支付,重新定义了零售场景。
交通领域正在经历机器学习带来的颠覆性变革。自动驾驶技术通过车载传感器收集路况数据,再由机器学习模型实时决策加速、刹车、转向,有望彻底解决人为驾驶失误导致的交通事故。智能交通系统则能根据车流量数据动态调整红绿灯时长,缓解城市拥堵。在物流行业,机器学习优化配送路线,让快递运输效率提升 30% 以上,既降低了成本,又减少了碳排放。
尽管发展迅速,机器学习仍面临诸多挑战。数据质量是首要难题,标注错误、样本偏见等问题会导致模型 “学坏”,比如招聘模型可能因历史数据中的性别偏见而歧视女性求职者。模型的 “黑箱” 特性也令人担忧 —— 当自动驾驶汽车发生事故时,人们难以解释算法为何做出某个决策,这在医疗、司法等关键领域可能引发信任危机。此外,隐私保护与数据利用的平衡、算法伦理的规范等问题,都需要技术突破和制度建设共同解决。
未来,机器学习将朝着更智能、更可靠、更通用的方向演进。联邦学习技术让多个机构在不共享原始数据的情况下联合训练模型,在保护隐私的同时提升模型性能;可解释性 AI 的发展将揭开算法的 “黑箱”,让决策过程变得透明;而通用人工智能的探索,则试图让机器拥有像人类一样举一反三的学习能力,适应各种复杂任务。这些技术突破不仅会推动机器学习在更多领域落地,更将深刻改变人类与机器的协作方式。
从塞缪尔的跳棋程序到如今的智能系统,机器学习用六十余年的发展证明,数据中蕴藏着改变世界的力量。它不是取代人类的工具,而是延伸智慧的桥梁 —— 让医生更精准地诊断,让科学家更高效地探索,让普通人的生活更便捷。当机器从数据中不断学习成长,人类社会也在这一过程中迈向更智能、更高效的未来。或许有一天,我们回望此刻,会发现机器学习带来的不仅是技术进步,更是一场关于智慧与创新的全新启蒙。
免责声明:文章内容来自互联网,本站仅提供信息存储空间服务,真实性请自行鉴别,本站不承担任何责任,如有侵权等情况,请与本站联系删除。

