最近,prompt learning——提示学习 这个方法可谓风靡一时,作为一个刚刚读了两三篇论文,还没有窥见人工智能这座大冰山一个小角的研一菜鸡,也好奇的(导师的指导)跑到这个前沿,东看看,西瞧瞧,道听途说来一点小知识,在这里分享记录一下,可能只是管中窥豹,如有纰漏还请各位大佬指出。
Prompt这个方法源自我不大熟悉的NLP领域,自从Transformer被提出、BERT发布以来NLP领域就发生了一场剧变,基于Transformer自监督训练的模型大行其道,在这段时间里,NLP领域形成了一个范式——“预训练-微调”
随着这种模式的发展(卷~),在一众强大的预训练模型中冒出了一个怪物,GPT-3。它出生名门,由OpenAI团队研发;身材壮硕,拥有1750亿参数;知识渊博,使用45TB数据进行训练;并且腰缠万贯,光训练这个模型就花了近乎千万美金。自带光环的GPT-3其效果也是相当的强劲。这里放个吹GPT-3的B站视频看一下。

金光闪闪的GPT-3马上引起了人们的关注,在学术圈激起了千层浪花。只需将自然语言的提示信息(prompt)和任务示例(demonstration)作为上下文输入给GPT-3,它就可以在零样本或小样本的情况下执行任何NLP任务,不需要对基础架构进行一丁点的微调。这种令人惊讶的泛化能力当然人人艳羡,尤其是对于那些手头吃紧(没有数据)的领域。
于是人们便开始思考
GTP-3强大的泛化能力,可以做到零样本学习,那我们是不是可以借鉴它的方式,来提升小样本学习的性能。大模型学到的知识是不是已经足够了,我们能不能不改动预训练模型了,换个思路,让下游的任务来靠近预训练模型就这样,仿照GPT3给出自然语言的提示信息的方法,一条全新的道路prompt,就开启了。

对于prompt的详细介绍这里主要参考刘博士写的这篇专栏刘鹏飞:近代自然语言处理技术发展的“第四范式”
前面说到NLP领域的一个范式“预训练-微调”,这个范式利用那些 已经在大规模 未标记 数据上通过 自监督学习完成预训练 的模型,让它们在下游任务上使用 少量人工标记数据 进行微调。这个模型其实挺不错,效率高,并且在小样本学习当中十分有效。
而prompt方式在这里又将开辟一个新的范式,“预训练-提示-预测”。采用prompt方法的模型,大部分都不会去改动预训练模型的参数。它们转而对下游任务下手,将下游任务的输入输出形式改造成适合预训练模型的样子。
这两种方法本质上,都是要让预训练模型和下游任务之间更加贴近,结成联姻,从而能够诞生出在具体任务上发挥出色的模型。
在原先“预训练-微调”的方式下,也许是时机不够成熟或是预训练模型本身不够强大,预训练模型不得不“献出自己的一部分”(改动预训练模型自身的参数),去迁就下游任务,以此来成全这门“喜事”。而如今时代变了,预训练模型累了,它不再做出让步,于是众下游任务屁颠屁颠跑来“舔”预训练模型,自愿变成预训练模型喜欢的样子,而预训练模型也回应它们的期待,产生了意想不到的效果。

接下来我们具体的说一下prompt,prompt是怎么样让下游任务改变自己,并赢得预训练模型的芳心的。

Prompt,也就是 提示,就按其字面理解,它就是伴随着输入一起,给予模型的一种上下文,它告诉、指导模型接下来你应当要做什么任务,是一个提示。或者换一种说法,就是前面说的它能够将下游任务改造成预训练模型期望的样子。
举一个例子:
我们的 预训练模型 是GPT,bert这样的模型,
我们的 下游任务 是 句子的情感分类问题。现在我拿到一句话”我喜欢这本电影”
我要判断“我喜欢这个电影” 这句话的情感(“正面” 或者 “负面”)
对于下游任务来说
我们的输入X:我喜欢这本电影
输出Y应该是:正面y+或者负面y-我们使用prompt的方法去改造下游任务,让我们的预训练模型可以做这个任务,那我们可以将这句话变成一个完型填空。
在”我喜欢这本电影”这个输入后面,
加上一个模板”[X]整体上来看,这是一个 [Z] 的电影”
即“我喜欢这个电影,整体上来看,这是一个 __ 的电影”在这里面,[Z]是我们预训练模型要预测的内容,“我喜欢这个电影,整体上来看,这是一个[Z]的电影”这样完形填空式的输入是预训练模型喜欢且擅长做的输入形式。
之后,我们给出两个选项,让模型预测。
A:无聊的 B:有趣的
其中选项A就是无聊的对应的是负面情感,B有趣的对应的就是正面情感。
Z=A -> X=y+ Z=B -> X=y-
就这样,一个下游情感分类的任务改造成了预训练模型可以处理的形态。
对于上面这个例子,总体来讲,因为预训练的语言模型,在之前的训练当中很有可能看过类似的”我喜欢这本电影,它他太有趣了“这种类似的话,所以会给选项中的A一个很高的概率,由此判断出,我喜欢这本电影,这是一个正面情感的句子。
但是在这里,一个合适的prompt(提示)对于模型的效果至关重要,像是提示的长度提示词汇的位置等等,一点prompt的微小差别,可能会造成效果的巨大差异。
比如,我们离谱一点,你在上面的话中加一个但字,”我喜欢这本电影,但这本电影是___”,很明显预测出来的东西就完全相反了。

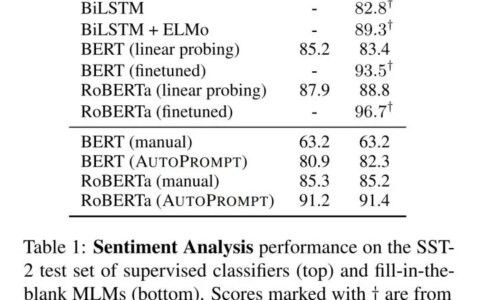
上图可以明显的看到,模型在下游任务中的表现对于prompt的好坏十分敏感,模型的效果波动非常大。一个合适的prompt提示,对于模型和下游任务的适配十分重要。
所以现阶段prompt方法再做的大部分事情就是
设计一个合适的提示模板,来创造一个完形填空的题目设计一个合适的填空答案,创造一个完型填空的选项以此来设计,怎么样给模型一个最好的提示,让下游任务能够更加适配预训练模型。
由于,我主要还是在学CV方面的内容,所以这里还是想简单介绍一下,从NLP领域借鉴过来的prompt的方法在CV当中的应用。
在CV中用prompt最早的应该就是clip这个项目了,也许因为他跟GPT-3一样都是openai做的?同样的,Clip也是使用了巨量的数据训练的模型。(4亿的图像文本对)。
跟上面类似的,在CLIp模型中,我们输入一个X,只不过这里的X从一个句子变成了一个图片,后面也是同样的给一个prompt模板。

比如我给一张狗的图片,要做一个分类任务,那么给的模板就是a photo of [Z],
输入:[X],a photo of [Z]。 就prompt方面来说这两个地方的形式是一样的。
同样的对于cilp这个预训练语言模型来说,在它看过的4亿张图片里面可能就有跟这张图类似的狗的照片,然后那个图片配的文字与狗相关。模型选dog这个选项的概率就会比较高。
总体来讲
Prompt并不会提升模型本身的性能,而是找到一个方法来激发模型的潜力,找到模型的上界。使用prompt做法的好处是显而易见的:
只要我找到了一个合适的prompt,就可以用一个预训练模型完成大量任务,不需要对于每个特定的任务再进行训练和微调。并且Prompt对于小样本学习提升明显,甚至能够使模型在没有看过任何样本的情况下也能够有良好的性能。
免责声明:文章内容来自互联网,本站仅提供信息存储空间服务,真实性请自行鉴别,本站不承担任何责任,如有侵权等情况,请与本站联系删除。