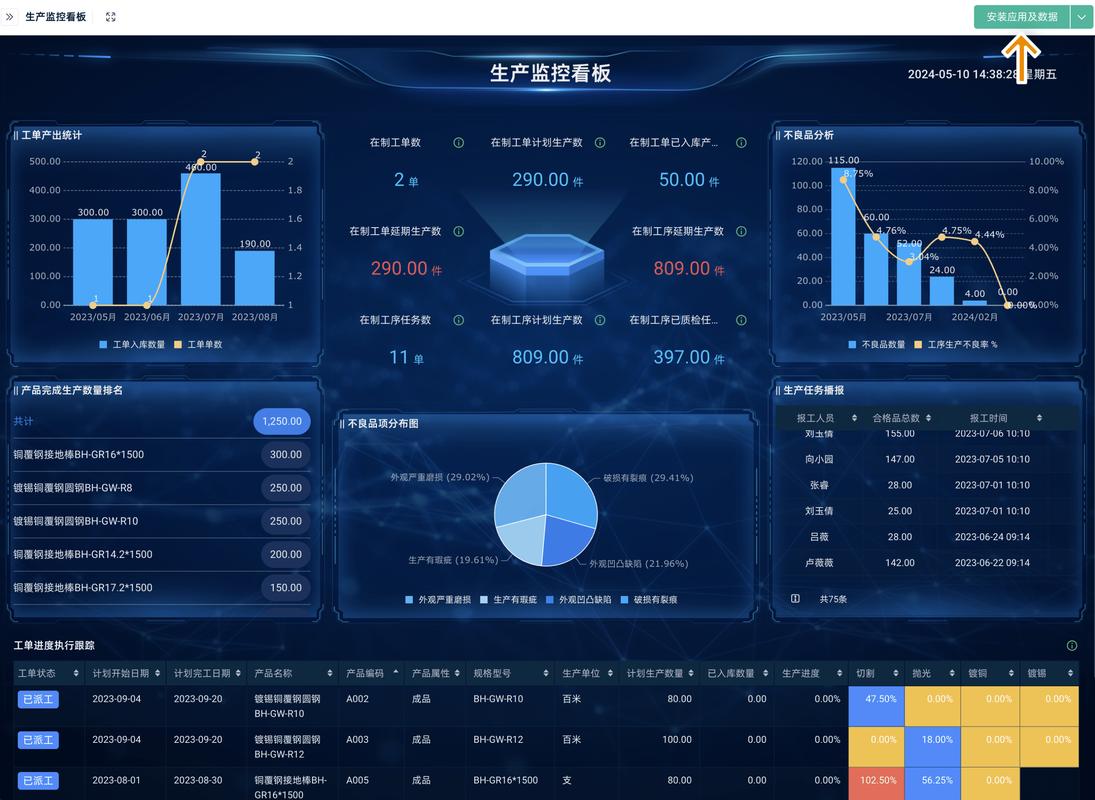
机器学习在工业预测性维护中的真实实践
说实话,干工业这行十多年,最头疼的不是设计,不是工艺,是设备趴窝——半夜电话一响,整个人能直接弹起来。三年前在一条冲压线上,凌晨两点电机烧了,停产八小时,直接损失小二十万。那种滋味,真是... 打那以后就开始琢磨,怎么让机器学会说话。
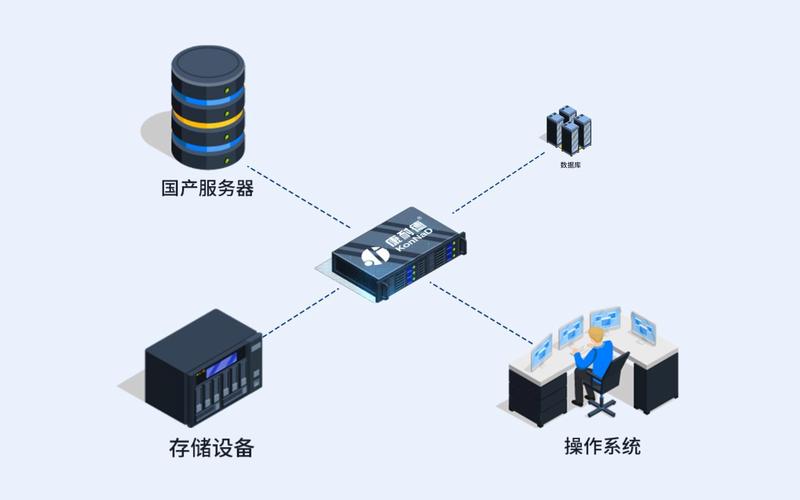
 预测性维护系统传感器安装现场图
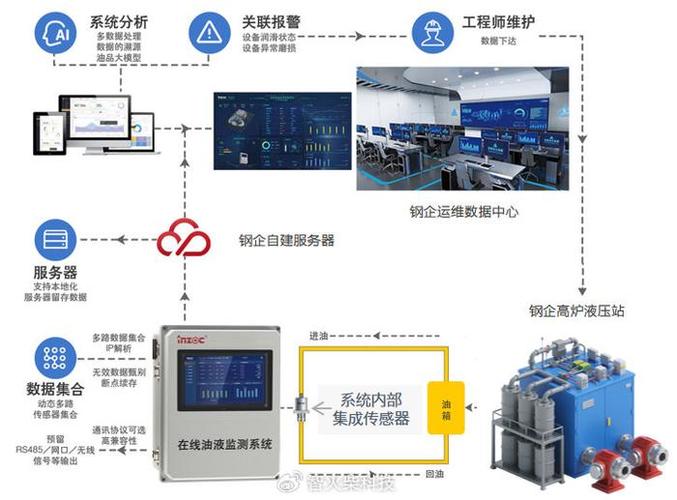
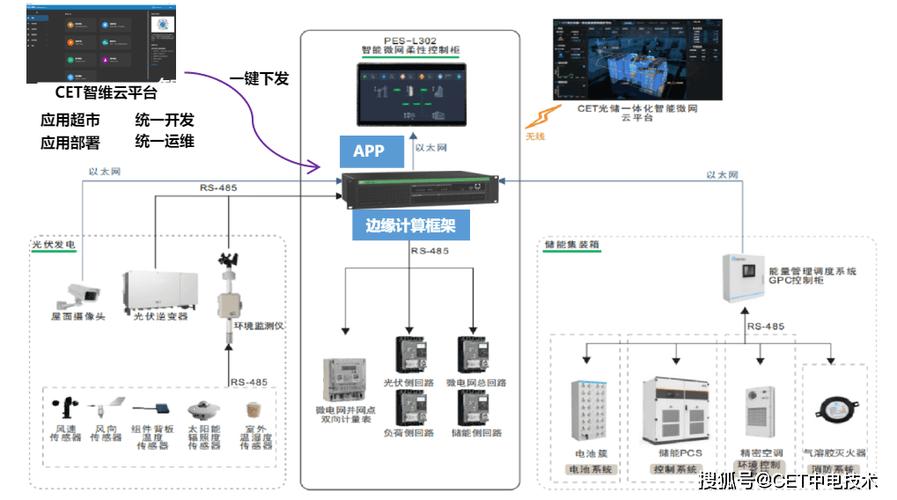
边缘计算设备部署在机床控制柜内
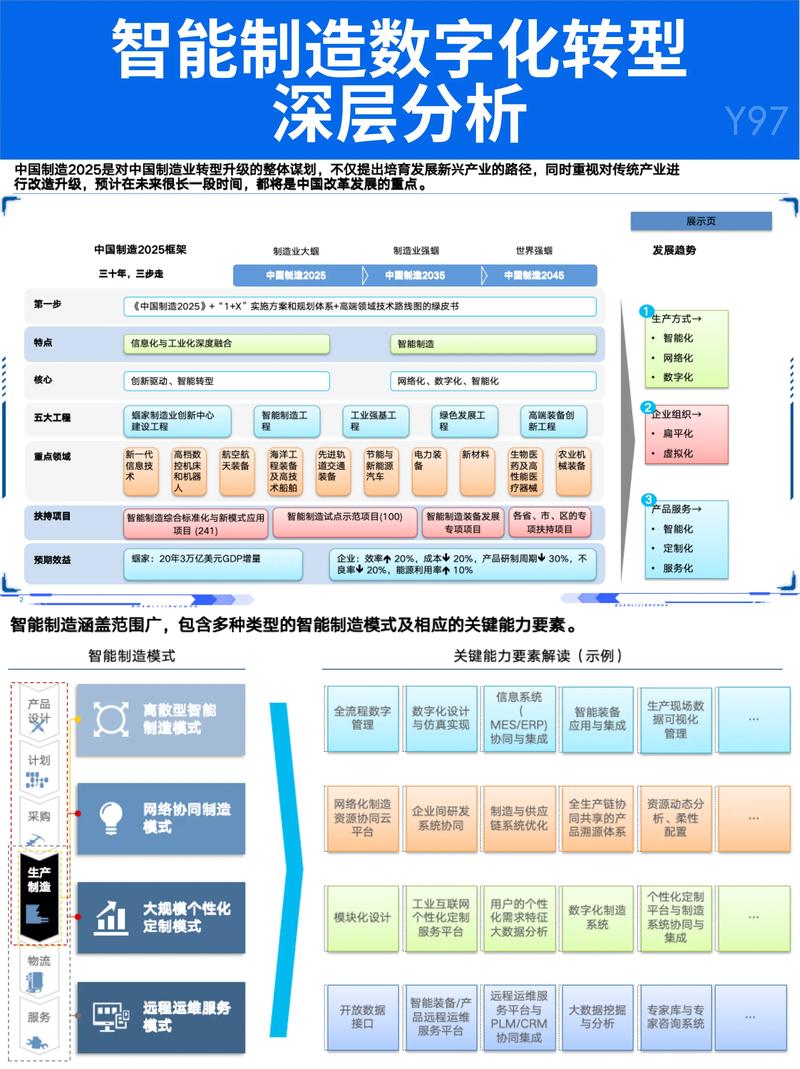
机器学习除了预测故障还能干啥
其实工艺优化更来钱。 比如焊接机器人,电流、电压、送丝速度这些参数,以前全靠老师傅凭感觉调。我们用高斯过程回归,把缺陷率从 1.2% 压到 0.3%,一年省了三十多万返修费。而且模型还能给出置信区间,告诉操作工“这组参数有 85% 的概率不出气孔”,比老师傅那句“我觉得行”靠谱多了。
说到视觉检测,传统算法调阈值累死人,光照一变就得重来。 现在卷积神经网络,哪怕零件表面有油污,照样能揪出几十微米的划痕。上个月出个趣事,模型误把零件编号钢印当成裂纹报警,后来加了字符识别模型做过滤才解决。这些边角料的故事,不亲手干过真不知道。
最后吐个槽:很多企业一听“机器学习”就觉得要招算法博士,其实开源框架现在这么成熟,PyTorch、TensorFlow Lite 直接往上套就行。倒是有经验的工艺专家和懂设备的工程师,这才是真正缺的。👉 懂工业的人用工具,比纯算法的人摸索工业快十倍。
问:这些模型后续怎么维护?需要持续喂数据吗?
答:必须的。概念漂移是常态。我们搞了个在线学习框架,每隔一周用新积累的数据增量训练,模型自动更新权重,还加了监测机制——一旦精确率跌破阈值,自动回滚到上一个稳定版本。 这招救了急,尤其是季节性生产波动大的工厂。❗ 记住,没有一劳永逸的模型,工业现场是活的。
预测性维护系统传感器安装现场图
边缘计算设备部署在机床控制柜内
机器学习除了预测故障还能干啥
其实工艺优化更来钱。 比如焊接机器人,电流、电压、送丝速度这些参数,以前全靠老师傅凭感觉调。我们用高斯过程回归,把缺陷率从 1.2% 压到 0.3%,一年省了三十多万返修费。而且模型还能给出置信区间,告诉操作工“这组参数有 85% 的概率不出气孔”,比老师傅那句“我觉得行”靠谱多了。
说到视觉检测,传统算法调阈值累死人,光照一变就得重来。 现在卷积神经网络,哪怕零件表面有油污,照样能揪出几十微米的划痕。上个月出个趣事,模型误把零件编号钢印当成裂纹报警,后来加了字符识别模型做过滤才解决。这些边角料的故事,不亲手干过真不知道。
最后吐个槽:很多企业一听“机器学习”就觉得要招算法博士,其实开源框架现在这么成熟,PyTorch、TensorFlow Lite 直接往上套就行。倒是有经验的工艺专家和懂设备的工程师,这才是真正缺的。👉 懂工业的人用工具,比纯算法的人摸索工业快十倍。
问:这些模型后续怎么维护?需要持续喂数据吗?
答:必须的。概念漂移是常态。我们搞了个在线学习框架,每隔一周用新积累的数据增量训练,模型自动更新权重,还加了监测机制——一旦精确率跌破阈值,自动回滚到上一个稳定版本。 这招救了急,尤其是季节性生产波动大的工厂。❗ 记住,没有一劳永逸的模型,工业现场是活的。
预测性维护:不再凭经验猜
传统维护要么坏了再修,要么定期换件。坏处太大,可定期换也糟心——很多零件明明还能扛半年,硬给换下来,浪费。真正要命的是突然性失效,轴承从正常到抱死可能就几秒,温度传感器根本来不及反馈。但振动频谱会提前好几天出现异常。人耳朵听不出,机器学习可以。 记得第一次看到轴承故障特征抓取得那么准,我差点拍桌子。 模型趴在历史数据上啃了一周,最后输出一条告警:“4号磨床主轴,72小时内保持架碎裂概率92%”。半信半疑拆开检查——保持架已经裂了三颗滚子,再转半天绝对散架。这玩意简直神了。 问:机器学习模型真的能提前几天预测故障吗?是不是数据够多就行? 答:不完全是。关键在于特征工程,那帮搞算法的经常忽略工业噪声。传感器采上来的信号,比如加速度计波形,直接扔给模型就是找死。得先做预处理——低通滤波滤掉电机谐波,再提取时域、频域几十个统计量,峰度、偏度、峭度系数这些。然后还得根据工况分段,负载变化时振动特征完全不同,不分段就混成一锅粥。 我们有个模型最开始把换刀时的冲击当成故障,闹过笑话。现在用孤立森林做异常点剔除,准确率上去了不少。 预测性维护系统传感器安装现场图
预测性维护系统传感器安装现场图
工业落地时的那些坑
实验室里 Accuracy 99% 的模型,到现场可能连 60% 都不到。为啥?数据漂移。去年帮一家注塑机厂做螺杆磨损预测,训练数据都来自夏天,冬天一到,液压油黏度变了,模型开始疯狂误报。 现场工程师差点拔了网关。后来用迁移学习,拿少量冬季数据微调最后一层,总算稳住了。 还有标签的问题。 设备不是总有完备的维修记录,很多时候只记“更换轴承”,不写失效模式。我们只好用无监督学习,先拿自编码器学正常状态,一旦重构误差变大就报警,再由专家去判断具体故障类型。这种半监督的路子反而更实用。 问:中小型工厂想上这种系统,成本高吗?需要什么样的基础? 答:很多人觉得上机器学习得先搞数字孪生,建大数据平台,没几百万下不来。其实不然。💡 如果只针对关键设备做试点,比如一台加工中心主轴,加装传感器的钱也就三五千,边缘计算盒子跑个轻量级模型,几百块搞定。数据采集直接用OPC UA拉PLC信号就行,不需要额外布线。 当然,要是有二十台以上设备,那还是得上私有云,用容器化部署,方便管理。我们给一家汽配厂做过方案,一期投入不到八万,三个月收回成本。✅ 边缘计算设备部署在机床控制柜内
边缘计算设备部署在机床控制柜内
机器学习除了预测故障还能干啥
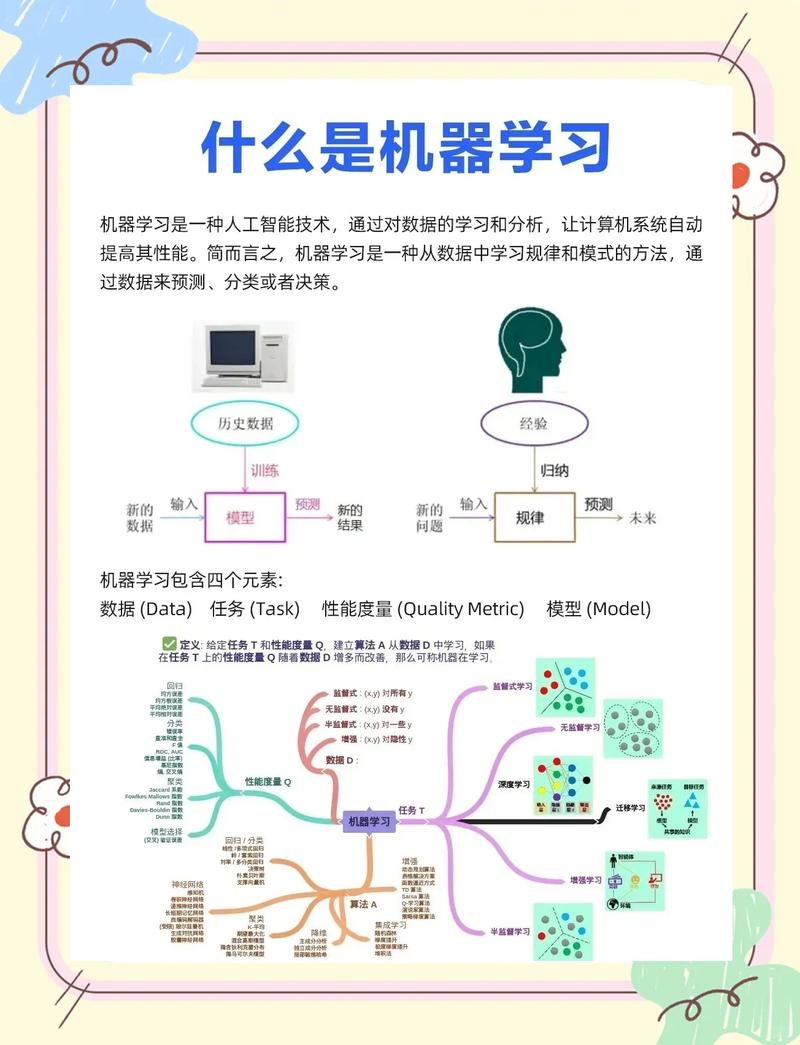 机器学习除了预测故障还能干啥
其实工艺优化更来钱。 比如焊接机器人,电流、电压、送丝速度这些参数,以前全靠老师傅凭感觉调。我们用高斯过程回归,把缺陷率从 1.2% 压到 0.3%,一年省了三十多万返修费。而且模型还能给出置信区间,告诉操作工“这组参数有 85% 的概率不出气孔”,比老师傅那句“我觉得行”靠谱多了。
说到视觉检测,传统算法调阈值累死人,光照一变就得重来。 现在卷积神经网络,哪怕零件表面有油污,照样能揪出几十微米的划痕。上个月出个趣事,模型误把零件编号钢印当成裂纹报警,后来加了字符识别模型做过滤才解决。这些边角料的故事,不亲手干过真不知道。
最后吐个槽:很多企业一听“机器学习”就觉得要招算法博士,其实开源框架现在这么成熟,PyTorch、TensorFlow Lite 直接往上套就行。倒是有经验的工艺专家和懂设备的工程师,这才是真正缺的。👉 懂工业的人用工具,比纯算法的人摸索工业快十倍。
问:这些模型后续怎么维护?需要持续喂数据吗?
答:必须的。概念漂移是常态。我们搞了个在线学习框架,每隔一周用新积累的数据增量训练,模型自动更新权重,还加了监测机制——一旦精确率跌破阈值,自动回滚到上一个稳定版本。 这招救了急,尤其是季节性生产波动大的工厂。❗ 记住,没有一劳永逸的模型,工业现场是活的。
机器学习除了预测故障还能干啥
其实工艺优化更来钱。 比如焊接机器人,电流、电压、送丝速度这些参数,以前全靠老师傅凭感觉调。我们用高斯过程回归,把缺陷率从 1.2% 压到 0.3%,一年省了三十多万返修费。而且模型还能给出置信区间,告诉操作工“这组参数有 85% 的概率不出气孔”,比老师傅那句“我觉得行”靠谱多了。
说到视觉检测,传统算法调阈值累死人,光照一变就得重来。 现在卷积神经网络,哪怕零件表面有油污,照样能揪出几十微米的划痕。上个月出个趣事,模型误把零件编号钢印当成裂纹报警,后来加了字符识别模型做过滤才解决。这些边角料的故事,不亲手干过真不知道。
最后吐个槽:很多企业一听“机器学习”就觉得要招算法博士,其实开源框架现在这么成熟,PyTorch、TensorFlow Lite 直接往上套就行。倒是有经验的工艺专家和懂设备的工程师,这才是真正缺的。👉 懂工业的人用工具,比纯算法的人摸索工业快十倍。
问:这些模型后续怎么维护?需要持续喂数据吗?
答:必须的。概念漂移是常态。我们搞了个在线学习框架,每隔一周用新积累的数据增量训练,模型自动更新权重,还加了监测机制——一旦精确率跌破阈值,自动回滚到上一个稳定版本。 这招救了急,尤其是季节性生产波动大的工厂。❗ 记住,没有一劳永逸的模型,工业现场是活的。 


![原创
青岛24小时道路救援拖车-附近24小时流动补胎[距离100米]](http://p3.itc.cn/images01/20230405/44ac03ca51fa4a3da21ab84adae75102.jpeg)