工业大数据:别只盯着“大”,脏数据能把产线逼疯
上个月去常州一家注塑厂,车间主任老李拉着我吐槽,说他们花了两百万上的“工业大数据平台”,现在成了摆设。我问为啥。他指着一排老旧的注塑机说,传感器倒是加了不少,温度、压力、振动,每秒吐几千条数据,可传上来的东西——啧,三分之一是乱码,还有三分之一数值离谱得像在梦游。他随便调出一条记录:模具温度显示零下15度。要知道车间里热得我衬衫都湿透了。我当场笑出声。笑完又觉得悲哀。这事儿太常见了。大数据大数据,一个个都冲着那个“大”字去,却忘了数据本身——会咬人的。
说实话,工业圈现在有个怪现象。很多老板一听“数字化转型”,立马拍板要上大数据,恨不得把所有设备都连上网。可钱砸下去,往往连最基本的信号都采不对。这就好比你买了最贵的音响,却放了一盘磁带,还是发霉的那种。聊胜于无?不,比没有更糟——噪声会淹没真正的有用信息。工业数据的价值,从来不在数量,而在质量。这句话我逢人便讲,听得进去的少。大家都被互联网那套“流量思维”带偏了。
数据采集:别小看一根线
搞工业的人都知道,设备底层那点事,远比想象中脏乱差。二三十年的老机床,连个通讯接口都没有,你要怎么取数据?就算有,协议往往是私有的,像西门子的 Profibus、三菱的 CC-Link,没点功夫根本搞不定。更头疼的是模拟量信号——4-20mA 电流环,看着简单吧?接线稍微松一点,干扰就进来了,数值飘得妈都不认。我见过最离谱的案例:一台数控车床的主轴负载,因为接地不良,每到下午两点就飙到满量程。查了三个月,才发现是隔壁车间一台冲床开工时的电磁干扰。这种问题,平台能分析出来?做梦。
所以,数据治理的第一步,是物理层的可靠采集。别迷信“即插即用”,也别轻信某厂销售吹嘘的边缘网关什么都能接。你得有人下到现场,一根线一根线地捋,一个变量一个变量地校准。前阵子我们给一家轴承厂做振动监测,光传感器的安装位置就折腾了四天。磁座安装、胶粘、打孔攻丝,每种方式对高频信号的衰减都不一样。这些细节,才是工业大数据的根基。
 工业传感器安装在注塑机上的特写图
工业传感器安装在注塑机上的特写图
数据清洗:30%的时间在洗,70%的精力在骂人
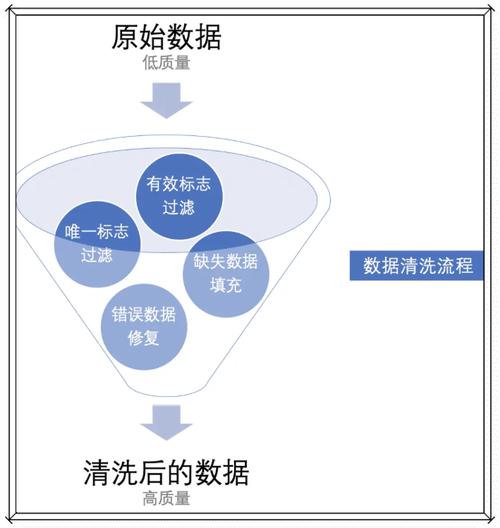 数据清洗:30%的时间在洗,70%的精力在骂人
数据清洗:30%的时间在洗,70%的精力在骂人
即便采集链路完美了,原始数据依然脏得可怕。缺失值、异常值、重复记录……还有更隐蔽的:同一台设备,换了个操作工,同样的加工参数,出来的产品尺寸就是有细微偏差。数据不会告诉你,是因为老王喜欢在换刀后多按一次对刀仪,而小李习惯按两次。这些“人因”需要额外标签才能捕捉。很多项目死在数据清洗上。不是技术难,是太琐碎,太熬人。算法工程师坐不住,现场工程师又不懂怎么标注有意义。结果,喂给机器学习模型的,还是“垃圾”。
问:工业数据清洗有什么特别的地方?
答:和互联网数据清洗完全两码事。电商数据可能删掉重复 ID、补充缺失地址就行了。工业数据要结合物理约束:比如一台电机的电流不可能在0.1秒内从10A跳变到100A,除非短路。那么这种跳变就该被标记或平滑。更麻烦的是时间序列对齐——不同传感器的采样频率不同,振动可能2000Hz,温度才1Hz,要对齐到同一时间轴上,还要考虑传输延迟。没有领域知识做清洗,等于闭着眼开车。
问:中小企业没钱请数据科学家,怎么弄?
答:三步走。第一,先把能稳定采到的十几个关键变量盯牢,别贪多。比如注塑机就看熔体温度、注射压力、保压时间这三板斧,七八成的缺陷能关联出来。第二,用简单的统计阈值报警,而不是一上来就搞 AI。超过均值±3σ就推送给老师傅手机,让他们人工判断。第三,积累半年到一年的干净数据后,再考虑上轻量级机器学习模型,比如随机森林做异常检测。千万别一上来就建“数据湖”,那玩意儿对中小企业就是个沼泽,会陷进去的。
从数据到决策:一个预测性维护的真实账单
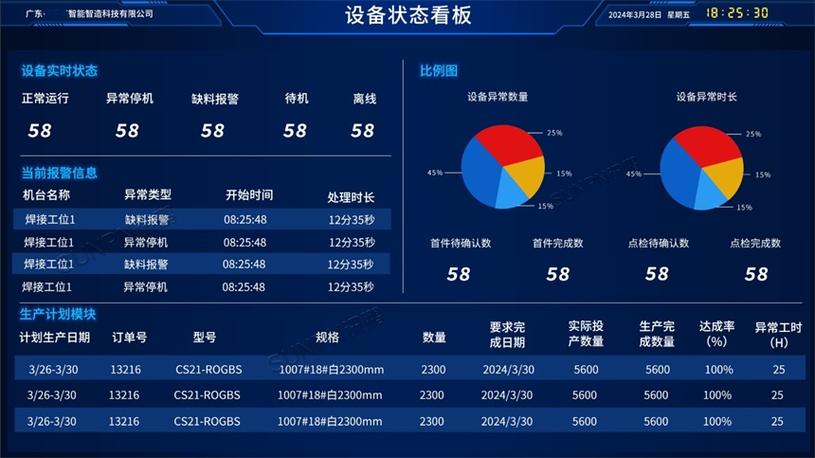
理论很丰满。讲个实际的。去年我们给一家汽车零部件厂做冲压机预测性维护。产线上六台800吨闭式压力机,每台三十多个传感器,振动、温度、油液颗粒度、滑块位移……数据源源不断灌进时序数据库。项目开始头两个月,数据组天天和维修班吵架:报警阈值设得太灵敏,凌晨三点打电话说振动超标,老师傅爬起来一看,没事,只是换了个模具。后来学乖了,让模型跟着人学。把每次维修记录和更换备件的时刻作为标签,往回倒追数据特征,发现真正有用的不是振动绝对值,而是特定频段的能量迁移,加上冲压次数累积的衰减趋势。又花了三个月,模型总算安静了——只在真的快出故障时,提前4-8小时预警。全年非计划停机时间降了70%。
 冲压机传感器布置与预测性维护看板
冲压机传感器布置与预测性维护看板
这笔账怎么算?一条冲压线停一小时,损失大概四万块,直接成本。这还没算赶工期的空运费、客户罚款。所以那套系统半年就回本了。但话说回来,如果没有前面几个月的“脏活累活”,没有老师傅半夜被冤醒的怒火,这事成不了。工业大数据落地的核心,从来不是算法多炫,而是人、数据、机器之间的磨合。
边缘计算:在数据产生的地方做算数
这两年“边缘计算”很火,工业圈也跟着热。可很多厂家把它搞复杂了。其实需求很朴素——很多设备现场,根本没条件把数据全传云端。注塑车间、压铸岛,温湿度高、粉尘大,网络还不稳定。你让一个铣床的振动数据先上云再做频谱分析,延迟一高,刀具早断了。所以必须在边缘侧做实时处理:采集、清洗、特征提取、本地推理,一条龙。只把结果和少量异常片段上传。这才是正道。
不过边缘端选型坑也不少。用 PLC 做简单逻辑还行,跑个轻量级模型就喘。工业 PC 又太贵。现在流行用带 AI 加速的嵌入式盒子,比如 NVIDIA Jetson 或者华为 Atlas。可你猜怎么着?散热是个大问题。密封机柜里夏天能到70度,盒子分分钟降频。又要加空调,能耗又上去了。哎,工业就没有舒舒服服升级的事。
问:边缘和云端怎么分工才合理?
答:我的经验是“三七分”。七成实时性要求高、数据量大的处理留在边缘:比如振动信号实时FFT、视觉瑕疵检测。三成需要全局视角、历史对比的交给云端:比如跨产线的OEE对比、能耗优化、模型定期更新。连接断了也不怕,边缘能独立存活。注意,边缘设备本身也要监控——有次我们一个边缘网关 SD 卡写满,直接罢工,产线数据全丢。所以,看护这套东西本身也是力气活。
说到底还是人的事
大数据、云计算、AI,全是工具。用不好,就是一堆昂贵的废铁。要想用好,得让车间里的人先接受。我见过一家阀芯厂,上了套 SPC 系统,自动采集产品尺寸。一开始操作工特别抵触,觉得是监视他们,有人偷偷拔网线。后来老板把数据用在正向激励上:谁做的批次尺寸最稳定,月底给额外奖金。态度立马转变,甚至有工人主动反映某个测头有点不准。你看,技术能发挥作用的前提,是把人的利益捋顺。
工业领域的大数据,绝不是什么神秘的灵丹妙药。它需要你扎进生产线,闻机油味,听机器响,跟老师傅抽烟聊天。那些整天在 PPT 里画智能工厂架构的,十个有九个半没真正解决问题。最后说句可能不中听的话:如果你的产线连最基础的5S都做不好,先别扯什么大数据了——先把地扫干净。