什么是机器学习?
机器学习是人工智能领域中的一个核心分支,它让计算机通过数据学习经验,从而在没有明确编程的情况下进行预测、判断或行为决策。简单来说,机器学习就是 “用数据训练模型,让计算机自动发现规律,从而实现预测或分类”。例如,通过分析大量邮件,让计算机学会区分正常邮件和垃圾邮件 。
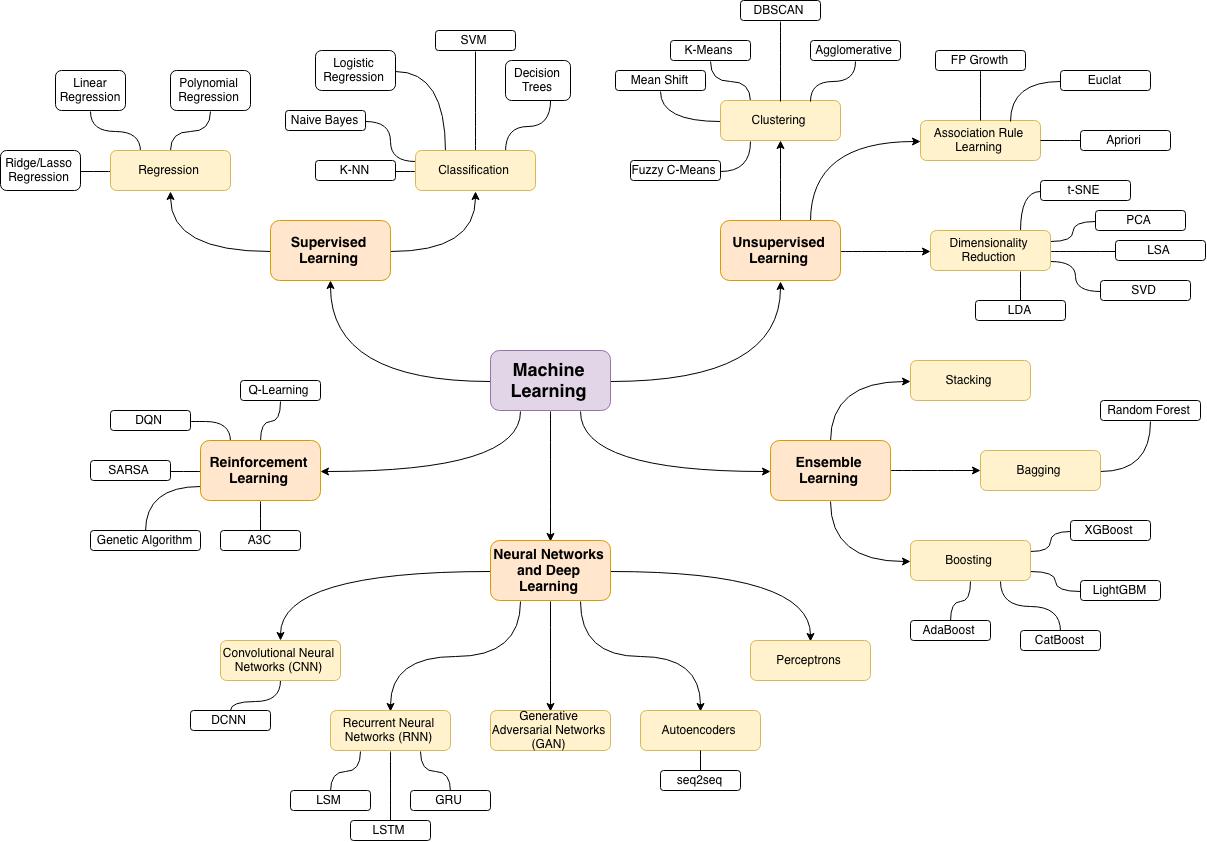
机器学习有哪些类型?
监督学习
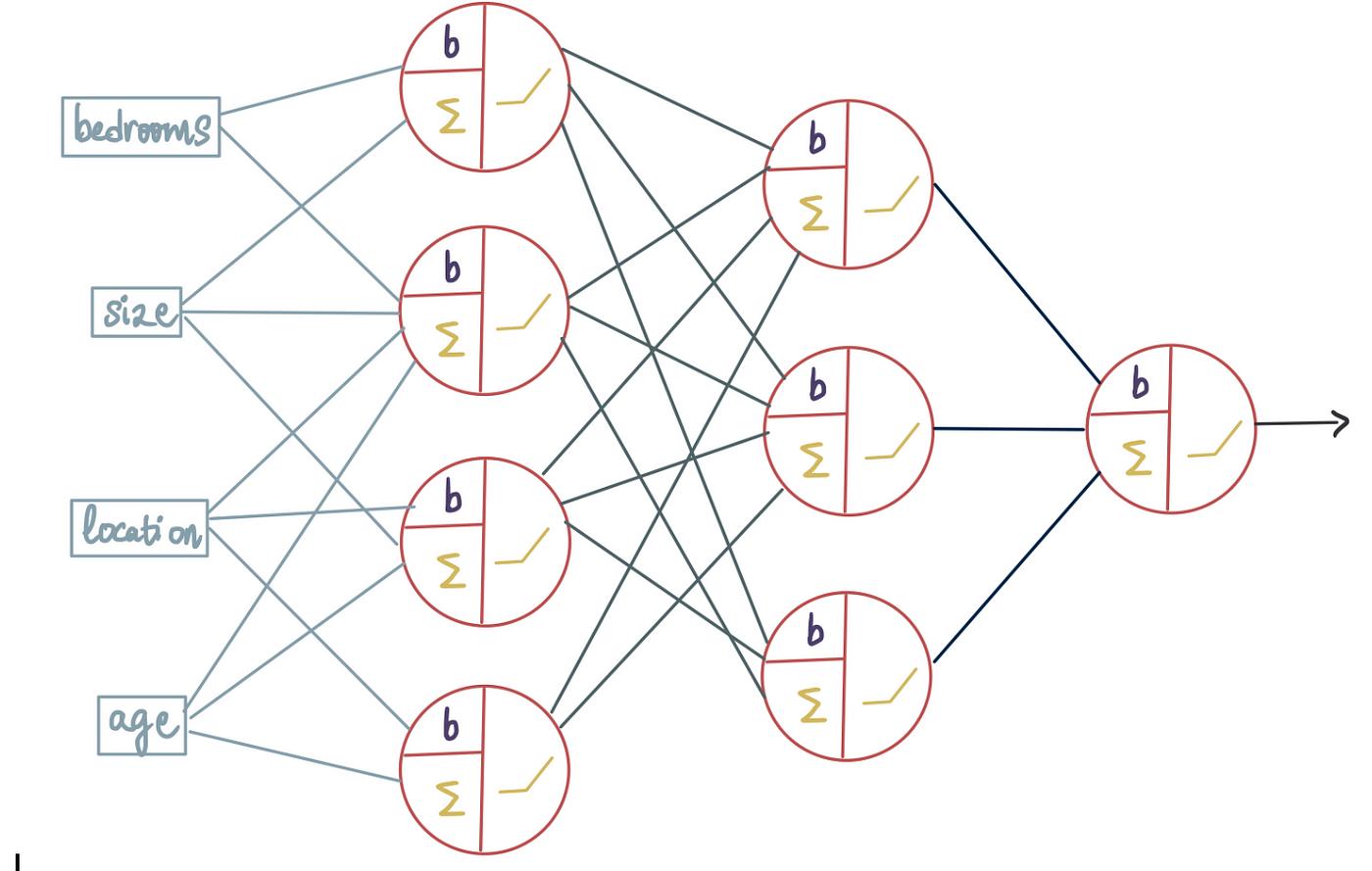
需要训练有标签的数据。比如在邮件分类中,先对用于训练模型的邮件标记为 “正常” 或 “垃圾”,模型学习这些标记数据后,就能对新邮件进行分类。常见算法有线性回归、逻辑回归、支持向量机、决策树、随机森林、K 近邻算法、朴素贝叶斯、神经网络等。
无监督学习
不需要显式地标记数据。像 K 均值聚类算法,它将未标记的点,通过计算不同点之间的距离均值,聚类成不同的组,以发现数据的内在结构。常见算法包括 K 均值聚类、层次聚类、主成分分析、独立成分分析、自编码器、高斯混合模型等 。
强化学习
通过与环境交互来学习策略,目标是最大化累积的奖励。以游戏 AI 为例,AI 在游戏环境中不断尝试不同动作,根据获得的奖励反馈,逐渐学会最优的游戏策略。常见算法有 Q 学习、深度 Q 网络、策略梯度方法、蒙特卡洛树搜索、Proximal Policy Optimization 等 。
机器学习有哪些应用领域?
机器学习应用范围极为广泛。在自然语言处理领域,可用于机器翻译、文本分类、语音识别等;图像识别方面,人脸识别、图像检索、物体识别都离不开它;电商、社交媒体平台中的商品推荐、内容推荐则是推荐系统的功劳;医疗诊断中,能辅助癌症诊断、疾病预测;金融风控里,可进行欺诈检测、信用评估;工业制造领域,用于质量控制、异常检测;还有自动驾驶中的视觉感知、路况识别,游戏智能里的游戏 AI 等 。
如何选择合适的机器学习算法?
这需要依据具体的问题和数据特性来决定。如果是预测连续值,比如房价预测,可考虑线性回归;若是分类问题,像判断邮件是否为垃圾邮件,逻辑回归、支持向量机等都可能适用。数据量少且特征维度低时,简单算法如朴素贝叶斯可能效果不错;数据量大且复杂,神经网络或许更合适。同时,还需考虑算法的训练时间、计算资源需求等因素 。
机器学习模型如何评估?
常用的评估指标有精确率、召回率、F1 值、AUC 等。精确率衡量模型正确预测的正例数量与模型总预测的正例数量之间的比例;召回率是模型正确预测的正例数量与数据中实际正例数量的比例;F1 值综合考虑精确率和召回率;AUC 用于衡量分类器的性能,反映了分类器在不同阈值下的真正例率和假正例率之间的权衡 。通过这些指标,可以评估模型的优劣,判断其是否满足实际应用需求。
相关搜索
机器学习算法、机器学习应用、监督学习、无监督学习、强化学习、模型评估指标
免责声明:文章内容来自互联网,本站仅提供信息存储空间服务,真实性请自行鉴别,本站不承担任何责任,如有侵权等情况,请与本站联系删除。