
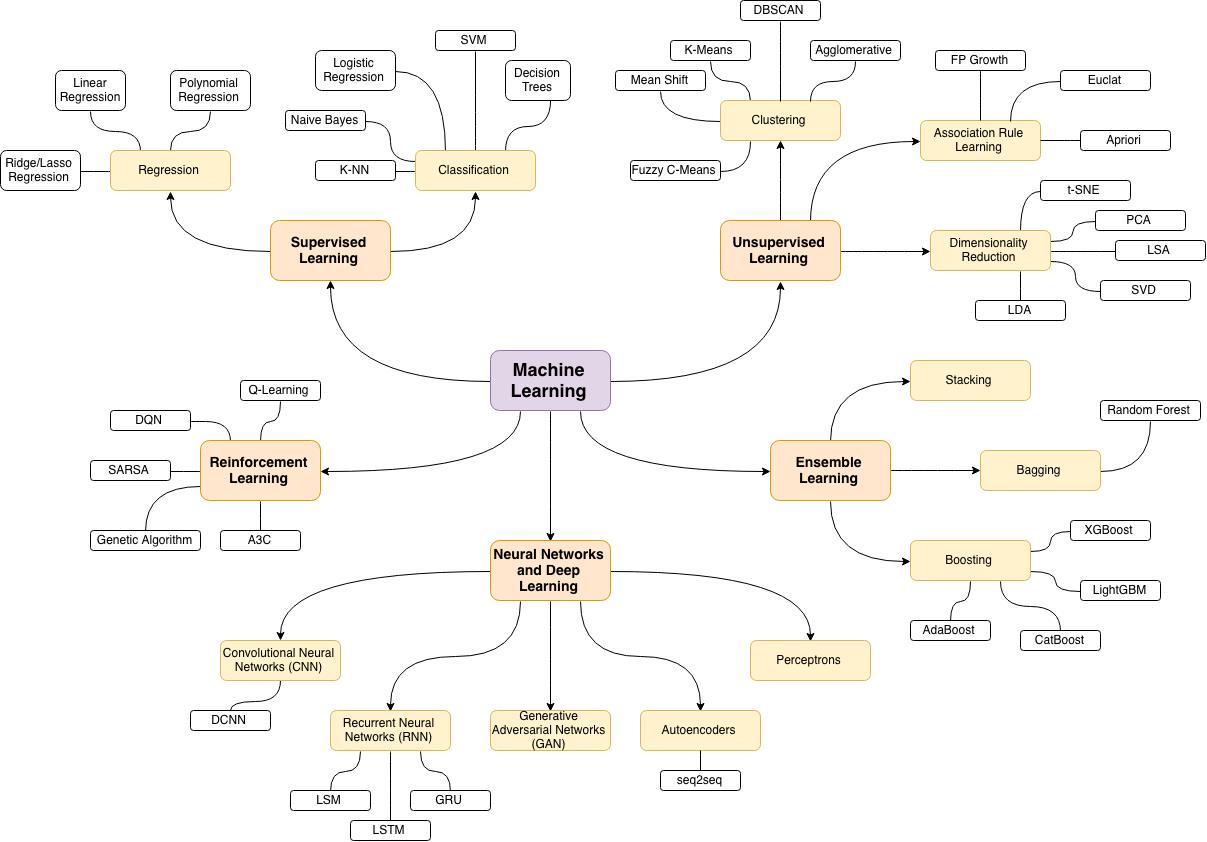
机器学习是人工智能领域的重要分支,它赋予计算机在无需明确编程的情况下自主学习和改进的能力。这种能力的核心在于通过算法对数据进行分析,从中挖掘潜在规律,并基于这些规律对未知情况做出预测或决策。从手机中的语音助手到电商平台的个性化推荐,机器学习正以润物无声的方式渗透到生活的各个角落,重塑着人们与技术交互的模式。
理解机器学习的核心原理,需要从数据、算法和模型三个维度展开。数据是机器学习的基石,任何模型的训练都依赖于大量高质量的样本。这些样本可以是文本、图像、声音等多种形式,但其共同特征是包含输入信息与对应输出结果 —— 例如识别垃圾邮件时,邮件内容是输入,“垃圾” 或 “正常” 的标签就是输出。算法则是处理数据的规则集合,它决定了计算机如何从数据中提取特征、建立关系。模型是算法作用于数据后的产物,是对现实规律的数学表达,如同一个经过训练的 “预测器”,能够对新输入做出反应。
监督学习是机器学习中应用最广泛的范式之一,其特点是利用带标签的数据进行训练。在这种模式下,算法通过对比预测结果与实际标签的差异不断调整参数,直至能够准确拟合数据规律。以识别手写数字为例,研究者会先准备数万张标注了具体数字的图片,算法通过分析这些图片中像素的分布特征,逐渐学会将特定的像素组合与 “0 – 9” 的数字对应起来。当新的手写数字图片输入时,训练好的模型就能依据已掌握的规律给出判断。常见的监督学习算法包括线性回归、决策树和支持向量机等,它们在房价预测、疾病诊断等场景中发挥着重要作用。
与监督学习不同,无监督学习处理的是无标签数据,其目标是发现数据中隐藏的结构或聚类模式。这种学习方式更接近人类对未知世界的探索 —— 在没有明确指导的情况下,通过观察事物的相似性进行分类。例如在客户分群场景中,电商平台可以收集用户的购买频率、消费金额等数据,无监督学习算法会自动将具有相似消费习惯的用户归为一类,帮助商家制定针对性的营销策略。聚类算法和降维算法是无监督学习的典型代表,其中聚类算法如 K – 均值算法能将数据划分为不同组别,降维算法如主成分分析则能在保留关键信息的前提下简化数据结构。
强化学习是另一种独特的学习范式,它通过与环境的交互不断优化行为策略。在这种模式下,智能体(如机器人、游戏角色)会根据环境反馈的 “奖励” 或 “惩罚” 调整自身行动,最终学会在特定场景中实现目标最大化。例如训练机器人行走时,机器人每迈出稳定的一步会获得正向奖励,摔倒则会受到惩罚,通过反复试错,机器人逐渐掌握保持平衡的技巧。强化学习在游戏 AI、自动驾驶等领域表现突出,AlphaGo 正是通过强化学习与人类棋手对弈,不断提升棋艺,最终实现了对顶尖选手的超越。
特征工程是机器学习流程中不可或缺的环节,它直接影响模型的性能。原始数据往往包含大量冗余信息,需要通过特征提取和转换,将其转化为更具代表性的形式。例如在处理文本数据时,研究者会将词语转换为向量,通过计算向量之间的距离衡量文本的相似度;在处理图像数据时,则会提取边缘、纹理等关键特征。好的特征能够凸显数据的本质规律,降低算法的学习难度。反之,若特征选择不当,即使采用复杂的算法,模型也难以达到理想效果。因此,特征工程需要结合领域知识和数据分析技巧,是对研究者经验与创造力的考验。
模型评估是验证机器学习效果的关键步骤,它通过一系列指标判断模型的泛化能力 —— 即模型对未见过的数据的预测准确性。常见的评估指标包括准确率、精确率、召回率和 F1 分数等,不同指标适用于不同场景。例如在疾病筛查中,召回率(即正确识别的患者占实际患者总数的比例)往往比准确率更重要,因为漏诊可能导致严重后果。交叉验证是常用的评估方法,它将数据集分为训练集和测试集,用训练集训练模型,用测试集检验效果,通过多次重复该过程减少偶然因素的影响,确保评估结果的可靠性。
机器学习在医疗领域的应用正深刻改变着疾病诊疗模式。通过分析医学影像数据,机器学习模型能够辅助医生识别早期肿瘤、眼底病变等细微异常,其准确率在某些场景下已接近甚至超过资深专家。在药物研发中,机器学习算法可以预测化合物的生物活性,缩短候选药物的筛选周期,降低研发成本。此外,基于患者的病历数据和基因信息,机器学习还能实现个性化治疗方案的制定,为癌症等复杂疾病提供更精准的干预策略。
金融行业也是机器学习的重要应用场景。银行利用机器学习模型分析客户的信用记录、收入水平等数据,评估贷款违约风险,提高信贷审批的效率和准确性。在股市预测中,算法通过处理海量的市场数据、新闻资讯,捕捉影响股价波动的潜在因素,为投资者提供决策参考。同时,机器学习在反欺诈领域发挥着关键作用,它能实时监测交易行为中的异常模式,及时识别信用卡盗刷、虚假交易等风险,保障金融安全。
教育领域的机器学习应用则致力于实现个性化学习。通过追踪学生的学习进度、答题情况等数据,系统能够分析每个学生的知识薄弱点,自动推送针对性的学习资源和练习题目。例如在语言学习 APP 中,机器学习模型会根据用户的错题类型,重点强化相关语法或词汇的训练;在在线教育平台上,系统能为不同学习能力的学生制定差异化的学习路径,让学习更高效、更具针对性。这种 “因材施教” 的模式,正在打破传统教育的标准化局限,为学习者带来更优质的体验。
尽管机器学习已取得显著成就,但它仍面临诸多挑战。数据质量问题是常见瓶颈,若训练数据存在偏见或缺失,模型可能会产生错误的预测,甚至强化社会不公 —— 例如某招聘算法因训练数据中存在性别偏见,导致对女性求职者的评分偏低。此外,机器学习模型的 “黑箱” 特性也引发争议,许多复杂模型如深度学习模型,其决策过程难以解释,这在医疗、司法等对透明度要求较高的领域可能带来信任危机。这些问题的解决,不仅需要技术的进步,还需要伦理规范的约束和跨学科的协作。
机器学习的魅力在于它将数据转化为智能的能力,这种能力的背后是数学、统计学与计算机科学的深度融合。从识别一张图片到辅助一场手术,从优化一次交易到设计一个学习计划,机器学习正以其独特的逻辑解读世界,为人类创造价值。随着技术的不断成熟,它将在更多领域展现潜力,但始终需要人类的智慧加以引导和规范,让智能真正服务于社会的进步与发展。
免责声明:文章内容来自互联网,本站仅提供信息存储空间服务,真实性请自行鉴别,本站不承担任何责任,如有侵权等情况,请与本站联系删除。
